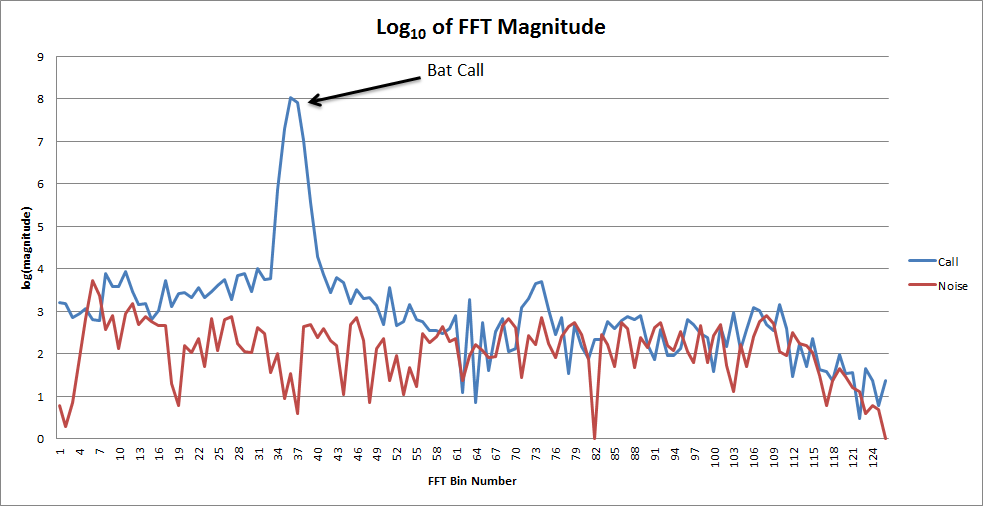
Whilst researching existing approaches to Bat Recognition, we discovered an open source MS Windows program called Bat BioAcoustics – http://sourceforge.net/projects/batbioacoustics/. This analyses a Bat recording and performs call detection to find where in the call there are bat signals, extracts audio features (such as maximum frequency) from the call, and then performs pattern matching (using Support Vector Machines) to categorise the calls to a species level. Although we are hoping to ultimately do real-time analysis, this program would be an excellent prototype to test if a phones CPU is fast enough to carry out the calculations. With this in aim, we decided to investigate porting Bat BioAcoustics to an iPhone.
Bat BioAcoustics (BBA) is written in C++, and has a number of dependent libraries:
- QT – A graphical user interface toolkit
- libsndfile – An open source audio format library
- FFTW – An open source fourier transform/DSP library
Although we could have attempted to compile these into our phone application, it would be better to replace them with the native iOS equivalents. We attempted to replace:
- QT with the iOS GUI toolkit
- libsndfile with the iOS CoreAudio library
- FFTW with the iOS vDSP library
Replacing QT with the iOS GUI toolkit
BioAcoustics runs as a native MS Windows application, with a graphical interface where users can choose the input files to analyse, and then it writes the results to an output file on disc. We removed from BioAcoustics the sections that controlled the interface, and we then converted the application to run from a command line. Supplying the information it previously obtained from the interface using the command line provided a convenient way to test it still worked without the QT toolkit. Once the other two libraries were replaced, we could replace the command line interface with a native iPhone interface.
Replacing libsndfile with iOS CoreAudio
libsndfile is an open source library that is used to read in various different audio formats, and extract the raw audio. Ultimately audio is just a series of numbers, but storing these literally is very inefficient. Instead they are normally compressed using a variety of different formats. For this project, we’re not interested in the details of how they are stored – we just need the raw audio data from the files – and so libsndfile provides a common set of methods to obtain this raw data without needing to know the details of the file format.
Apple provide a similar set of methods in their CoreAudio library, and so we will convert BioAcoustics to use these instead.
BioAcoustics code contained a wrapper class that simplified the details of calling libsndfile from the rest of the code. Instead of every piece of code that needed audio samples having to set up libsndfile itself, this class carried out the low level setup, leaving the rest of the code clearer by reducing the number of functions it needed to call. The wrapper has 2 fundamental methods:
bool SndFile::read(std::string const& path)
Audio SndFile::getAudio()
As long as our wrapper class kept the same methods and parameters, we could swap the classes from using libsndfile to CoreAudio without the rest of BioAcoustics noticing, which is exactly what we did. We wrote a new class that had the same method signatures, but instead of then using libsndfile to read the raw samples from the audio file format, we used iOS CoreAudio, as desribed at Audio on an iPhone.
We could now investigate replacing the DSP library FFTW with the iOS equivalent – vDSP
Replacing FFTW with the iOS vDSP library
FFTW is an open source Fourier/DSP library. BioAcoustics uses this to perform the low level signal analysis and to extract frequency-series information from the time-series call. Apple provide their own Fourier/DSP library called vDSP, also known as the “Accelerate Framework”.
As with libsndfile, BioAcoustics code contained a wrapper class that simplified the details of calling FFTW from the rest of the code. This wrapper has 3 fundamental methods:
setPlan(int &fftSize, window_type &window_t)
process(std::vector<float> &audioSamples, int &start)
getSpectrum(std::vector<float> &audioSamples, int &start)
We wrote a new class that kept the same method signatures, but instead of using FFTW to do the low level mathematics, we used the iOS vDSP library as described in Fourier Transforms on an iPhone. Replacing the BioAcoustics wrapper with our own meant that every time BioAcoustics thought it was calling FFTW, we actually used vDSP instead without it realising the difference.
Building the first iPhone App
Now these three things were in place, we could investigate building our first functioning prototype. Having replaced libsndfile and FFTW with native iOS equivalents, we could run BioAcoustics from the command line on a Mac, using the iPhone simulator. The next step is to write an iPhone user interface for it.
BioAcoustics is written in C++, but Apples user interface toolkit requires code to be written in Objective-C. Objective-C and C++ code can both run in the same application, but it can be tricky to avoid problems when they interact. To reduce the number of potential problems, we wanted as few points of contact between the iPhone GUI, and BioAcoustics as possible. To achieve this, we wrapped the entire BioAcoustics code into a library, that contains one fundamental method:
deque<Event> Bioacoustics::analyse(string path)
Here we can simply pass BioAcoustics the path of the file we would like to analyse, and it will return a list of custom Event objects, containing all the information about each detected call event. This means we can write all our GUI code in Objective-C as normal, we already have the BioAcoustics in C++, and we’ve minimised any potential problems for the interaction between them both.
In Action
So once this was all done, we had the first functioning prototype! It might not look too great yet, but it’s exciting to be able to test if an iPhone is capable of doing this level of analysis.
1) Choose from a list of files to analyse:
2) BioAcoustics is running:
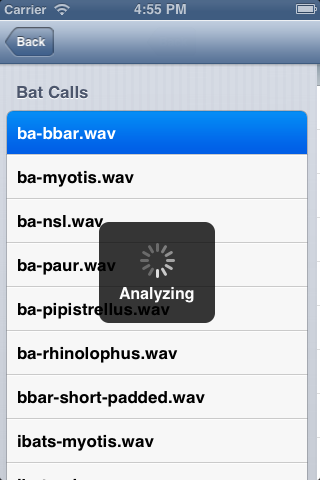
3) We have a list of detected Bat Calls:
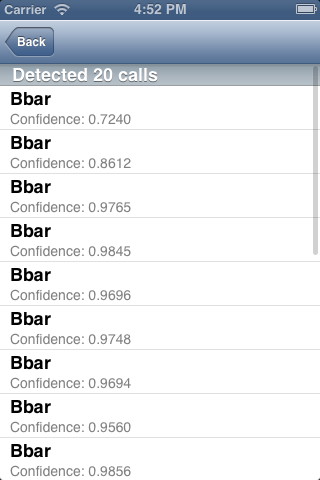
4) We can view some more information about each call:
Conclusion
Porting BioAcoustics to an iPhone has been a resounding success! It’s been quite a process but we’ve shown that it is possible to perform the level of audio analysis needed to automatically detect and recognise bat signals from supplied audio. Analysing a 14sec file took 5sec to perform, which also suggests it will be easily possible to run this analysis on a phone in realtime.
Because this was a prototype to test the concept, so far we have used a pre-supplied list of call sample files. The next stage will be to implement real time recording and analysis, which will need to use an external time-expansion bat detector. These are pieces of equipment that reduce the frequency of the ultrasonic audio from the bat down to a level that an iPhone is capable of recording. Once the iPhone can record the audio, we can attempt to analyse it in real time. Another useful enhancement would be to display realtime sonograms (spectrograms) on the phone, to aid researchers in their own visual analysis of the signal.